This is a post about my work for the big data programming course, where we could choose a topic within Deep learning to explore. I chose something I’m interested in: anime posters.
What is Anime?
Anime is a style of animation popular in Japan, but it is becoming more internationally recognized, with a growing fanbase.

Source
What was the purpose of this project?
This project has a purpose of being able to classify the genres with only an anime poster, this is important because one of the biggest catalogue of anime (myanimelist.net) has some entries with no genres or synopsis, Which instead of manually watching the show and classifying them, a trained model could classifying them instead, which makes it easier for recommender system to be able to recommend shows that might fit an user that doesn’t have much information about the show.
Previous project have been done as seen with this Github repo and this Journal entry, however, the journal entry has a high accuracy for predicting, what I could tell (it was in Indonesian) it predicts for single labels with softmax activation for the final layer, which forces the output to be added up to one, which makes it better at classifying for single labels, However, genres are a multi labeled problem which makes the Github repo more in line with what I’m trying to do.
The GitHub repo’s limitation is that it only compares against a single backbone, ResNet18, which is a small backbone to train with. When I look at the performance, I can see that the F1-score was around 0.49-0.5 on the validation set. So my goal for this project was to outperform this model with a better F1-score
The Data
The data was gathered from Kaggle, which contains all anime data entries up until 2023, which was needed for getting the genres, but it also contains links to the anime posters, which were downloaded to be able to do this project
After removing the unnecessary columns, I removed all entries that weren’t TV shows or movies. This was done because there are a lot of OVAs and other entries that, instead of having a poster, would have a random screenshot from the show, which isn’t exactly like a poster, more like a screen-grab.
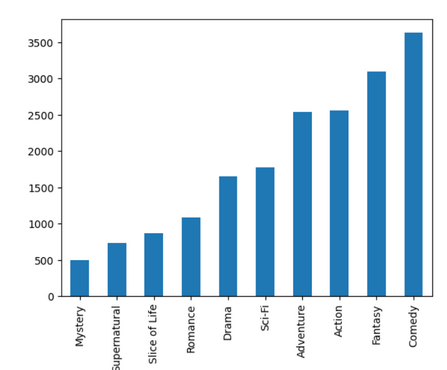
In the end, I had 9200 posters across genres I could use for multi-label classification. I also only kept the top 10 genres from the dataset because the original had around 20 genres, and the amount of data per genre (for example, suspense had few entries) wasn’t enough to train on all genres. I pruned the genres from the dataset, but if it had another genre in the top 10, I kept it. The setup for model training was 7200 training, 1000 validation, and 1000 test.
The Model
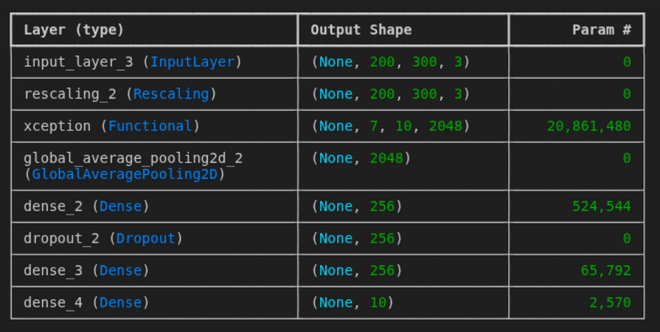
I first tried playing around to see if I could make my own model and what results it would bring; however, it showed no promise. So I decided to see whether adding a backbone with pretrained weights would yield better results. To fine-tune and see the results, I used EfficientNetv2-b0, Resnet50, and Xception as backbones with ImageNet-pretrained weights. With these, I used what the GitHub rep did. In hindsight, I could have experimented a bit more and maybe done some parameter tuning to make the best performance out of these models
After I had trained the model, I discovered that precision was good; however, Recall wasn’t improving much. After some googling, I discovered that to remedy this, I should change the loss function to BinaryFocalCrossentropy, which penalizes the model more when it misclassifies fewer labels than many in the dataset. I also did threshold tuning, which means I lowered the activation threshold for the final nodes to achieve a better F1 Score. This led to lower precision but higher recall (the model “guessed” more), which I did for each model separately.
I trained the model with the backbone layer’s weight being frozen for 5 epochs, then I trained the model for 50 epochs with early stopping if f1-score decrease with a patience of 5
The Results
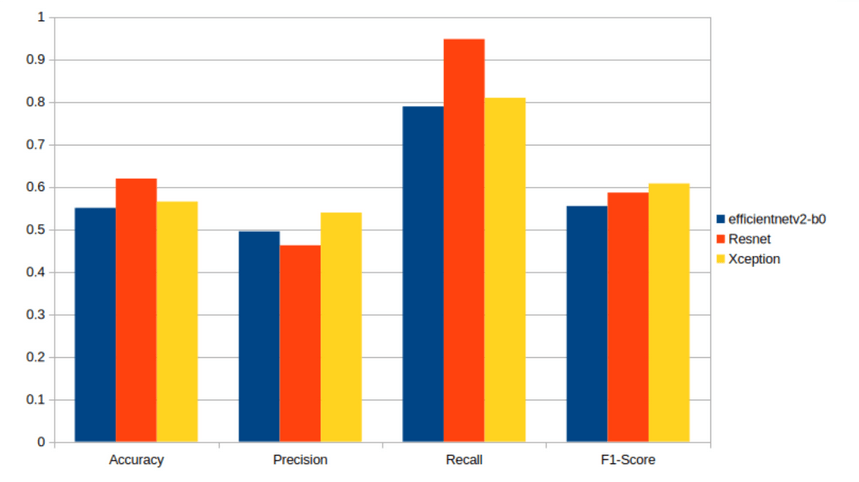
We can see that the best backbone model is Xception, which has the highest F1 value and precision. If recall and accuracy matter, then ResNet is better.
I also beat Wang’s model (Github), which had an F1 of 0.5. This was because I did threshold tuning and Wang did not, so the results are very satisfactory.
Some Real Examples
To show some real examples, I will showcase a few examples from the model

We can see that ResNet and EfficientNet perform well; however, Xception predicts “Slice of Life”. This might be because the picture has lighter colors than the rest. Also, the supernatural is interesting because the show has supernatural elements in it; however, the ground truth doesn’t contain it, which might be hindsight by the people labeling the data

We can see that it has a problem with Fantasy and Sci-fi, this might be because of the colors used in the poster being blue
(dark blue = Sci-fi, I guess)

I want to highlight Serial experiment lain prediction, because we can see that Xception guesses 7 out of 10 genres, which I think is pretty bad; however, we can see that the other models are more reasonable guesses
Limitations
I didn’t try different output layers, which might have yielded better results than those shown. I also didn’t try more pretrained models.
I also should have focused more on threshold tuning; instead of changing every single node’s activation threshold by the same amount, I should have tuned each node separately, which might have given better results.
When separating the data into training set, Validation set, Test set, I didn’t check the distribution of each label in these sets, which might give better or worse results, however, when I check the test set, there are at least 69 samples per label, for the future one might need to make this distribution better to be able to get better results and better training
Sidenote
I wrote this a month after finishing this project, so there might be details I missed. Please send me a message if I should clarify something

{kind=link}
Leave a comment